
In today’s data-driven world, efficient data management and workflow automation are key to unlocking the true potential of your business. Enter Kestra — an open-source, cloud-native data orchestration platform designed to streamline orchestration with simple YAML syntax and an extensive open-source Plugins library. In this blog post, I’ll talk about an architecture idea for an end-to-end process of an Extract, Load, Transform (ELT) pipeline in Kestra. I’ll also introduce and showcase some of the powerful Kestra Enterprise features that are available in their Enterprise product. Whether you’re new to Kestra or an experienced user, this post will provide you with valuable insights on leveraging the platform for your own ELT pipeline, and it will hopefully help you jumpstart into your Kestra ELT journey.
Let’s dive in, woohoo!
If you are new to Kestra I recommend reading my previous blogpost that talks about what Kestra is.
Quick note before diving in
- This blogpost is not a walkthrough — This blogpost will not dive into many details of the code, but will rather be an example you can use and build off of for your Kestra projects.
- This blogpost is meant to help new and existing Kestra users have a strong project environment and architecture setup for running ELT pipelines.
- This blogpost is also meant to showcase the potential uses of some Enterprise features.
Rick and Morty ELT Pipeline Starting Information
We will be using a “Rick and Morty ELT Pipeline” for our example in this blogpost. Below is some information on the pipeline that we will be walking through:
- The GitHub repository can be found here.
- The API used is the Rick and Morty basic API.
- The orchestration software used is Kestra, and there are Kestra Enterprises features used as well in the pipeline.
- The Extraction language used is Python.
- UV package manager is used
- The Transformation framework used is dbt core.
- The Cloud used is GCP Cloud.
- The DevOps Infrastructure-as-Code tool used is Terraform.
- The Repository uses a Dev Container environment, to ensure it works on any computer.
- GitHub Actions is used for CI/CD pipeline components.
Below is a diagram of the pipeline process:

This diagram is separated into two components:
Terraform
- The Terraform is in charge of creating the BigQuery tables, as well as other GCP resources that are not shown in the diagram (these are not shown to reduce clutter in the diagram — some items are: Artifact Registry Repo, BigQuery datasets, Google Cloud Storage (GCS) Bucket).
Kestra workflow
- The Kestra workflow is in charge of running the ELT pipeline start-to-finish. The first step is to extract data from the Rick and Morty API, and then we land data to GCS bucket as JSONL files, next we land the data from GCS to BigQuery, and our last step is to trigger a dbt core pipeline.
All of these steps utilize Kestra Plugins that we will cover.
About the Kestra Environment utilized
You will need to spin up your own Kestra environment, I recommend referencing the documentation on Kestra’s documentation page to do this.
In this project, I utilized a Raspberry PI and installed Kestra with Docker Compose. I will not be covering how to set up Kestra in a dev environment, as this is another topic, and following the previously referenced documentation should be sufficient in showing you how to set it up.
The Kestra Environment utilized had an Enterprise License; as a result, if you are using Open Source, you will need to make some changes:
- This Project utilizes Kestra GCP Batch Task Runner (Enterprise only). If you are using Open Source, you will need to use an Open Source Task Runner instead.
- This Project utilizes the effective Google Cloud Secrets Manager integration offered by Kestra Enterprise, if you are using open source, you will need to use Open Source secrets.
The Kestra Environment that I utilized is locked down and has a user authentication setup, and utilizes CloudFlare and a registered Domain.
The Repo Walkthrough (minus Kestra)
GitHub Actions
This repository has the following GitHub Actions in .github/workflows directory:
- run-dbt-ci — This is an action that executes the SQLFluff linter. It goes through the following steps — installing
uv, installing SQLFluff packages that are needed, and then executes the lint command with SQLFluff. This ensures that SQL code in our dbt models is consistent, easy-to-read, and clean. - run-dbt-deploy — This is an action that deploys the dbt Docker stage to GCP Artifact Registry. It uses a custom action that I wrote and builds/pushes the Docker Image to GCP Artifact Registry.
- run-python-ci — This is an action that executes isort, black formatting, and flake8 linting checks.
- run-python-deploy — This is an action that deploys the Python Docker stage to GCP Artifact Registry. It uses a custom action that I wrote and builds/pushes the Docker Image to GCP Artifact Registry.
- clear-gh-cache — This is an action that clears the GitHub Cache. It works alongside the two deploy GitHub Actions by making sure cache is cleaned up overtime on a CRON schedule.
Currently the Custom Action that I wrote uses GCP_Credentials_JSON, which is not a recommended approach for production due to GCP Service Account JSON never expiring unless manually expired. The recommended approach in production is to use Workload Identity Federation. This was set up for simplicity. You should use Workload Identity Federation in Production.
Extraction (Python)
This repository utilizes Python to extract data from the Rick and Morty API.
The Python code is all located in src . It is divided into two main modules:
- Core
- Integrations
Core holds the core API class, as well as utilities that are used in the Extraction and Landing-to-GCS process.
Integrations holds the entrypoint for our Kestra workflow to execute the actual Jobs for the Rick and morty API.
There are docstrings in the codebase, so I will be providing a high-level summary in this blogpost.
Our entrypoint for the Rick and Morty API is the src/integrations/rick_and_morty/main.py . We pass two variables:
uuid_str— UUID string that is referenced when loading the data from GCS to BigQuery. This is generated in Kestra.job_name— This is the job name of the job being executed. Possible options include — character, episode, location.
The main.py file calls the fetch_data method from fetch_data.py , which uses the API class in core/contrib/rick_and_morty .
Pydantic is used for validation and the files are converted to a list of dictionaries, which are then converted to JSONL format and uploaded to the GCS bucket.
Terraform
This repository utilizes Terraform for the Infrastructure-as-Code tool.
The Terraform folder houses all of the Terraform resources and variables. It is worth noting, that I utilized HashiCorp Cloud to manage the backend and to handle the Terraform variables/secrets.
The Terraform folder has the following files:
- variables.tf — This holds the variables that are used in
main.tf. In my setup these variables are filled in through the Variables feature in HashiCorp Cloud Workspace. - main.tf — This holds the Terraform declaration/setup, as well as the provider setup (Google Cloud), and the resources that we create.
You would need to update the organization and workspace name to your own, if you are using this repo for your environment.
dbt core
All dbt core processes are housed in the root dbt folder.
The models directory holds the staging and landing dataset models.
The macros directory holds macros that we can utilize throughout our models.
The dbt_project.yml file holds the configurations and settings for our dbt core project
The package-lock.yml and packages.yml holds information on what packages dbt deps downloads.
We don’t utilize either of the packages, we install, it’s more of showing it as an example.
The profiles.yml shows two profiles that dbt has, with default being used as the ‘default option’. Both of the profiles are authenticated to Google Cloud through “OAuth”. We authorize locally in the dev container through Google Cloud Application Default Credentials and when it runs in Kestra it will authenticate automatically to Compute Service Account in GCP since dbt will be ran as a GCP Batch Job (will discuss more about GCP Batch Jobs in Kestra Workflow section).
Dev Container Environment
This repository utilizes a Dev Container VS Code Extension for development.
It is worth noting that this repo was developed with VS Code in mind; as a result, the .devcontainer.json will need to be adjusted if you use a non-VS Code IDE.
It utilizes the .devcontainer.json file to tell VS Code what settings to use.
Here are some summarized bullets on the .devcontainer.json in the repository:
- utilizes Docker Compose services —
vs_code_dev_100 - installs extensions that help in the following areas: Python, dbt YML, GitHub Actions, Kestra, dbt, and Theme.
- sets settings — some notable settings are YAML using Prettier formatter and Python using Black formatter.
- the file associations are for dbt Power User Extension to work correctly
Docker Compose & Dev Container
The Docker Compose YAML is what the dev container uses. It is worth noting that we have an environemnt variable, DOCKER_DEFAULT_PLATFORM due to being on Mac Silicon Chip computer. It is also worth noting, that the user will need to copy the .env.local to .env and will need to fill out .env . The Docker Compose utilizes the vs_code_dev_100 Dockerfile stage, and it copies files from your local environment into the container (volumes) for directories. It is worth noting the following:
${HOME}/.configcopies over to/root/config— This is overkill, but it is responsible for getting the generated Google Application Default Credentials. You can and should make this more granular.
More detail on dev containers can be found here. This blogpost is meant to focus on Kestra within GCP; as a result, I will not dive into Dev Containers. I simply added it to the repo, as I prefer to use Docker with development.
You do not need to use the dev container for development if you have a different preference.
UV Python
I have started to recently use UV as it is extremely fast and easy to use.
The pyproject.toml file holds the settings and dependencies for Python. Specifically, we set our linting rules in it, as well as house our dependency and dependency groups.
Similar to the above, this is a Kestra-focused blogpost, so I will not dive into UV Python.
You do not need to use UV, if you have a different package preference.
The Kestra Workflow

The above Topology report within the Kestra Flow UI shows the path of the Workflow:
If Execute Fetch?
- Generate UUID string with Python Kestra Plugin
- Run all jobs in parallel that were selected in inputs. After jobs finish, land to BigQuery from GCS
If Execute dbt?
- Execute dbt build command on dbt
staging.landing_dataset.*pipeline.
Let’s walk through this workflow section by section.
ID and Namespace section
id: rick_and_morty_pipeline
namespace: pipelineIn this section we define our Workflow ID (immutable) and the namespace that the Workflow will be apart of.
Inputs section
inputs:
- id: execute_fetch
type: BOOLEAN
required: true
defaults: false
description: |
If True, this process will execute the extraction, otherwise extraction is skipped.
- id: jobs
type: MULTISELECT
required: true
defaults:
- character
- episode
- location
values:
- character
- episode
- location
description: |
Decide which jobs to fetch from.
- id: execute_dbt
type: BOOLEAN
required: true
defaults: false
description: |
If true, execute dbt, otherwise skip dbt.
- id: dbt_select_pattern
type: STRING
required: true
defaults: "staging.landing_dataset.*"
description: The dbt select pattern(s) to run dbt build on.
dependsOn:
inputs:
- execute_dbtIn this section we define our Kestra Workflow inputs. The repo utilizes Conditional Inputs, as well as Boolean/String/Multi-Select input types.
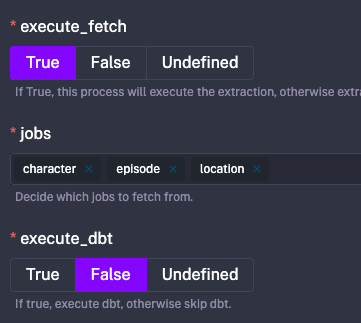
In the image you can see that the jobs input is showing because execute_fetch is True. And the dbt_select_pattern input is not showing, because execute_dbt is False.
Variables section
variables:
LANDING_GCS_BUCKET: "insert-your-landing-gcs-bucket-name"
KESTRA_STORAGE_BUCKET: "insert-your-kestra-storage-bucket-name"In the variables section, we are hardcoding two GCS bucket names that we need to reference in our workflow. Read more about variables here.
Tasks section
Execute Fetch
- id: if_execute_fetch
type: io.kestra.plugin.core.flow.If
condition: "{{ inputs.execute_fetch }}"
then:
- id: generate_uuid
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install --upgrade pip
- pip install kestra
script: |
from uuid import uuid4
from kestra import Kestra
Kestra.outputs({"uuid_str": str(uuid4())})
- id: parallel
type: io.kestra.plugin.core.flow.Parallel
concurrent: 3
tasks:
- id: if_job_selected_character
type: io.kestra.plugin.core.flow.If
condition: '{{ inputs.jobs contains "character" }}'
then:
- id: fetch_data_character
type: io.kestra.plugin.scripts.python.Commands
env:
GCP_PROJECT_ID: "{{ secret('GCP_PROJECT_ID')}}"
commands:
- python -m integrations.rick_and_morty.main --uuid_str {{ outputs.generate_uuid["vars"]["uuid_str"] }} --job_name character
containerImage: "us-central1-docker.pkg.dev/{{ secret('GCP_PROJECT_ID') }}/kestra/kestra-elt-pipeline-python:latest"
warningOnStdErr: false
taskRunner:
type: io.kestra.plugin.ee.gcp.runner.Batch
region: us-central1
bucket: "{{ vars.KESTRA_STORAGE_BUCKET }}"
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
machineType: "n2d-standard-2"
computeResource:
cpu: "2000"
memory: "8192"
- id: load_bq_from_gcs_jsonl_character
type: io.kestra.plugin.gcp.bigquery.LoadFromGcs
from:
- 'gs://{{ vars.LANDING_GCS_BUCKET }}/character_{{ outputs.generate_uuid["vars"]["uuid_str"] }}.jsonl'
destinationTable: "landing_dataset.character_table"
writeDisposition: WRITE_APPEND
createDisposition: CREATE_NEVER
autodetect: false
format: JSON
allowFailure: true
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"In this section, the Execute Fetch boolean input is being used to determine if fetches are executed.
If the boolean is True, then Kestra generates a UUID String through Python (There is a newly released way to do this with Pebble; as a result, this could be cleaned up). After the UUID String is generated, the fetching process starts in parallel. For each of the three jobs (Character, Location, Episode), a few tasks check if the job is selected, executes the job within the GCP Batch Task Runner, and loads the data from GCS to BigQuery.
Execute dbt
- id: if_execute_dbt
type: io.kestra.plugin.core.flow.If
condition: "{{ inputs.execute_dbt }}"
then:
- id: execute_dbt
type: io.kestra.plugin.dbt.cli.DbtCLI
env:
GCP_PROJECT_ID: "{{ secret('GCP_PROJECT_ID') }}"
containerImage: "us-central1-docker.pkg.dev/{{ secret('GCP_PROJECT_ID') }}/kestra/kestra-elt-pipeline-dbt:latest"
commands:
- dbt deps
- dbt build --select {{ inputs.dbt_select_pattern }}
taskRunner:
type: io.kestra.plugin.ee.gcp.runner.Batch
region: us-central1
bucket: "{{ vars.KESTRA_STORAGE_BUCKET }}"
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
machineType: "n2d-standard-2"
computeResource:
cpu: "2000"
memory: "8192"The execute dbt section is similar in that the boolean is checked, and if True, it runs through GCP Batch Task Runner.
I utilized GCP Batch Task Runner since I am hosting Kestra on a Raspberry PI, which I want to conserve resources on.
Which gives you the whole Workflow:
id: rick_and_morty_pipeline
namespace: pipeline
inputs:
- id: execute_fetch
type: BOOLEAN
required: true
defaults: false
description: |
If True, this process will execute the extraction, otherwise extraction is skipped.
- id: jobs
type: MULTISELECT
required: true
defaults:
- character
- episode
- location
values:
- character
- episode
- location
description: |
Decide which jobs to fetch from.
- id: execute_dbt
type: BOOLEAN
required: true
defaults: false
description: |
If true, execute dbt, otherwise skip dbt.
- id: dbt_select_pattern
type: STRING
required: true
defaults: "staging.landing_dataset.*"
description: The dbt select pattern(s) to run dbt build on.
dependsOn:
inputs:
- execute_dbt
condition: "{{ inputs.execute_dbt }}"
variables:
LANDING_GCS_BUCKET: "kestra_landing_bucket_1234567890"
KESTRA_STORAGE_BUCKET: "kestra-storage-bucket-391"
tasks:
- id: if_execute_fetch
type: io.kestra.plugin.core.flow.If
condition: "{{ inputs.execute_fetch }}"
then:
- id: generate_uuid
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install --upgrade pip
- pip install kestra
script: |
from uuid import uuid4
from kestra import Kestra
Kestra.outputs({"uuid_str": str(uuid4())})
- id: parallel
type: io.kestra.plugin.core.flow.Parallel
concurrent: 3
tasks:
- id: if_job_selected_character
type: io.kestra.plugin.core.flow.If
condition: '{{ inputs.jobs contains "character" }}'
then:
- id: fetch_data_character
type: io.kestra.plugin.scripts.python.Commands
env:
GCP_PROJECT_ID: "{{ secret('GCP_PROJECT_ID')}}"
commands:
- python -m integrations.rick_and_morty.main --uuid_str {{ outputs.generate_uuid["vars"]["uuid_str"] }} --job_name character
containerImage: "us-central1-docker.pkg.dev/{{ secret('GCP_PROJECT_ID') }}/kestra/kestra-elt-pipeline-python:latest"
warningOnStdErr: false
taskRunner:
type: io.kestra.plugin.ee.gcp.runner.Batch
region: us-central1
bucket: "{{ vars.KESTRA_STORAGE_BUCKET }}"
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
machineType: "n2d-standard-2"
computeResource:
cpu: "2000"
memory: "8192"
- id: load_bq_from_gcs_jsonl_character
type: io.kestra.plugin.gcp.bigquery.LoadFromGcs
from:
- 'gs://{{ vars.LANDING_GCS_BUCKET }}/character_{{ outputs.generate_uuid["vars"]["uuid_str"] }}.jsonl'
destinationTable: "landing_dataset.character_table"
writeDisposition: WRITE_APPEND
createDisposition: CREATE_NEVER
autodetect: false
format: JSON
allowFailure: true
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
- id: if_job_selected_episode
type: io.kestra.plugin.core.flow.If
condition: '{{ inputs.jobs contains "episode" }}'
then:
- id: fetch_data_episode
type: io.kestra.plugin.scripts.python.Commands
env:
GCP_PROJECT_ID: "{{ secret('GCP_PROJECT_ID')}}"
commands:
- python -m integrations.rick_and_morty.main --uuid_str {{ outputs.generate_uuid["vars"]["uuid_str"] }} --job_name episode
containerImage: "us-central1-docker.pkg.dev/{{ secret('GCP_PROJECT_ID') }}/kestra/kestra-elt-pipeline-python:latest"
warningOnStdErr: false
taskRunner:
type: io.kestra.plugin.ee.gcp.runner.Batch
region: us-central1
bucket: "{{ vars.KESTRA_STORAGE_BUCKET }}"
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
machineType: "n2d-standard-2"
computeResource:
cpu: "2000"
memory: "8192"
- id: load_bq_from_gcs_jsonl_episode
type: io.kestra.plugin.gcp.bigquery.LoadFromGcs
from:
- 'gs://{{ vars.LANDING_GCS_BUCKET }}/episode_{{ outputs.generate_uuid["vars"]["uuid_str"] }}.jsonl'
destinationTable: "landing_dataset.episode_table"
writeDisposition: WRITE_APPEND
createDisposition: CREATE_NEVER
autodetect: false
format: JSON
allowFailure: true
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
- id: if_job_selected_location
type: io.kestra.plugin.core.flow.If
condition: '{{ inputs.jobs contains "location" }}'
then:
- id: fetch_data_location
type: io.kestra.plugin.scripts.python.Commands
env:
GCP_PROJECT_ID: "{{ secret('GCP_PROJECT_ID')}}"
commands:
- python -m integrations.rick_and_morty.main --uuid_str {{ outputs.generate_uuid["vars"]["uuid_str"] }} --job_name location
containerImage: "us-central1-docker.pkg.dev/{{ secret('GCP_PROJECT_ID') }}/kestra/kestra-elt-pipeline-python:latest"
warningOnStdErr: false
taskRunner:
type: io.kestra.plugin.ee.gcp.runner.Batch
region: us-central1
bucket: "{{ vars.KESTRA_STORAGE_BUCKET }}"
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
machineType: "n2d-standard-2"
computeResource:
cpu: "2000"
memory: "8192"
- id: load_bq_from_gcs_jsonl_location
type: io.kestra.plugin.gcp.bigquery.LoadFromGcs
from:
- 'gs://{{ vars.LANDING_GCS_BUCKET }}/location_{{ outputs.generate_uuid["vars"]["uuid_str"] }}.jsonl'
destinationTable: "landing_dataset.location_table"
writeDisposition: WRITE_APPEND
createDisposition: CREATE_NEVER
autodetect: false
format: JSON
allowFailure: true
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
- id: if_execute_dbt
type: io.kestra.plugin.core.flow.If
condition: "{{ inputs.execute_dbt }}"
then:
- id: execute_dbt
type: io.kestra.plugin.dbt.cli.DbtCLI
env:
GCP_PROJECT_ID: "{{ secret('GCP_PROJECT_ID') }}"
containerImage: "us-central1-docker.pkg.dev/{{ secret('GCP_PROJECT_ID') }}/kestra/kestra-elt-pipeline-dbt:latest"
commands:
- dbt deps
- dbt build --select {{ inputs.dbt_select_pattern }}
taskRunner:
type: io.kestra.plugin.ee.gcp.runner.Batch
region: us-central1
bucket: "{{ vars.KESTRA_STORAGE_BUCKET }}"
serviceAccount: "{{ secret('GCP_SERVICE_ACCOUNT_JSON') }}"
projectId: "{{ secret('GCP_PROJECT_ID') }}"
machineType: "n2d-standard-2"
computeResource:
cpu: "2000"
memory: "8192"Note:
- the GCP Batch Task Runner settings I set are too high, more of just using as an example. You would want to select a machine type that is optimized for your workload.
Some images:

Conclusion
In this blogpost, we learned about a ELT architecture pattern and GitHub repo set up for a Kestra orchestration project. Feel free to star and use the blogpost repository as a reference in your Kestra journeys.
To conclude, I want to thank the Kestra team for making this incredible, reliable software.
Happy Coding!

